
XML Pipeline
Processes large XML files one instance of a repeatable structure at a time.
With this transform, Data Services does not need to read the entire XML input into memory then build
an internal data structure before performing the transformation. An NRDM structure is not required to
represent the entire XML data input. Instead, the XML_Pipeline transform uses a portion of memory to
process each instance of a repeatable structure, then continually releases and reuses memory to steadily
flow XML data through the transform
an internal data structure before performing the transformation. An NRDM structure is not required to
represent the entire XML data input. Instead, the XML_Pipeline transform uses a portion of memory to
process each instance of a repeatable structure, then continually releases and reuses memory to steadily
flow XML data through the transform
XML_Pipeline helps us to convert the XML Schema data or the nested schema data in to normal tabular data.
XML Schema Structure

The above structure is an example of a nested structure.
To convert this in to a normal structure (refer to the image bellow) we use XML_Pipeline transformation.

So Using the XML Pipeline transformation you can convert the nested structure to a normal structure.
Please find the bellow demo job.

The source can be a XML File source / XML Message source.
XML_Pipeline Transformation
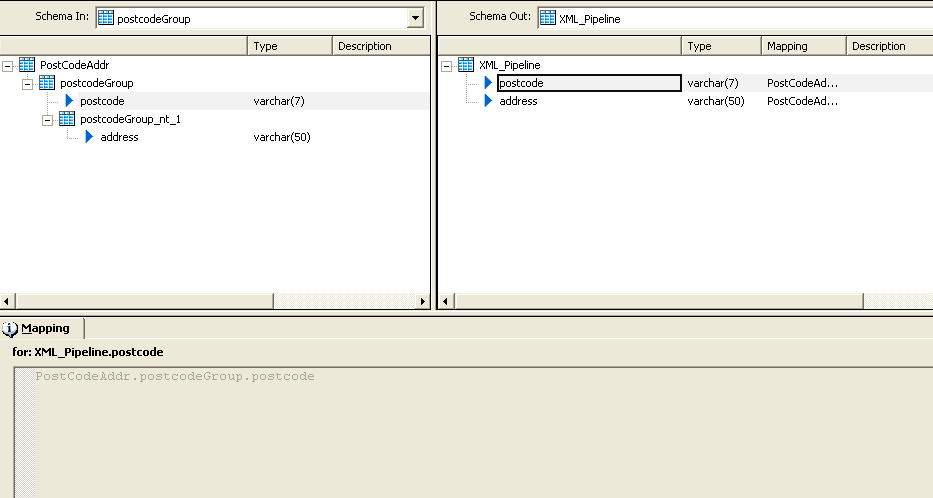
In general query transformation you cannot drag the columns “postcodeGroup” and “address” directly
from schema in to the schema out. For that you have to first un-nest the nodes. But using XML_Pipeline
transformation you can directly drag those columns to the schema out.
Select the column “postcode Group” and drag that to the schema out, next select address from the schema
in and drag that to the schema out.
in and drag that to the schema out.
Connect it to a template table and execute the job.
One the job execution is completed; you can find the output in the bellow format.
