
Table Comparison
Compares two data sets and produces the difference between them as a data set with rows flagged
as INSERT, UPDATE, or DELETE.
as INSERT, UPDATE, or DELETE.
The Table_Comparison transform allows you to detect and forward changes that have occurred since
the last time a target was updated.
the last time a target was updated.
Data Inputs
The data set from a source or the output from another transform. Only rows flagged as NORMAL are
considered by the transform. This data is referred to as the “input data set”. The specification for a
database table to compare to the input data set. This table is referred to as the “comparison table”.
considered by the transform. This data is referred to as the “input data set”. The specification for a
database table to compare to the input data set. This table is referred to as the “comparison table”.
If the input data set contains hierarchical (nested) data, Data Services includes only the top-level
data in the comparison and does not pass nested schema through to the output.Use caution when
using columns of data type real in this transform.Comparison results are unpredictable for this
data type.
data in the comparison and does not pass nested schema through to the output.Use caution when
using columns of data type real in this transform.Comparison results are unpredictable for this
data type.
Comparison method
Select a method for accessing the comparison table:
- Row-by-row select — Select this option to have the transform look up the target table using
to the number of rows the transform will receive as input.
- Cached comparison table — Select this option to load the comparison table into memory.
This option is best when you are comparing the entire target table. Data Services uses pageable
cache as the default. If the table fits in the available memory, you can change the cache type to
in-memory in the data flow Properties.


- Sorted input — Select this option to read the comparison table in the order of the primary key
To take advantage of this option,the order of the input data set must match order of all primary key
columns in the Table_Comparison transform. If this is already the case, drag primary key columns
from the input schema in the Table_Comparison transform into the Input primary key columns box.
Using a sequential read,Data Services reads comparison table in the order of primary key columns.
columns in the Table_Comparison transform. If this is already the case, drag primary key columns
from the input schema in the Table_Comparison transform into the Input primary key columns box.
Using a sequential read,Data Services reads comparison table in the order of primary key columns.
Input primary key column(s)
The input data set columns that uniquely identify each row. These columns must be present in the
comparison table with the same column names and data types. Drag the column(s) from the input
schema into the Input primary key columns box. The transform selects rows from the comparison
table that match the values from the primary key columns in the input data set.
If values from more than one column are required to uniquely specify each row in the table, add
more than one column to the Input primary key columns box. You cannot include nested schema
in the Input primary key columns list.
comparison table with the same column names and data types. Drag the column(s) from the input
schema into the Input primary key columns box. The transform selects rows from the comparison
table that match the values from the primary key columns in the input data set.
If values from more than one column are required to uniquely specify each row in the table, add
more than one column to the Input primary key columns box. You cannot include nested schema
in the Input primary key columns list.
Compare columns
(Optional)Improves performance by comparing only the subset of columns you drag into this box
from the input schema. If no columns are listed, all columns in the input data set that are also in
the comparison table (that are not of the long or blob data type or the Generated key column) are
used as compare columns.You do not need to add primary key columns to the compare column list.
They are always compared before the compare columns apply. The compare columns apply only if
the primary key value from the input data set matches a value in the comparison table.
If the primary key value from the input data set does not match a value in the comparison table,
from the input schema. If no columns are listed, all columns in the input data set that are also in
the comparison table (that are not of the long or blob data type or the Generated key column) are
used as compare columns.You do not need to add primary key columns to the compare column list.
They are always compared before the compare columns apply. The compare columns apply only if
the primary key value from the input data set matches a value in the comparison table.
If the primary key value from the input data set does not match a value in the comparison table,
Data Services generates an INSERT row without further comparisons. If the primary key value from
the input data set matches a value in the comparison table and values in the non-key compare
columns differ in the corresponding rows from the input data set and the comparison table,
Data Services generates an UPDATE row with the values from the input data set row.
the input data set matches a value in the comparison table and values in the non-key compare
columns differ in the corresponding rows from the input data set and the comparison table,
Data Services generates an UPDATE row with the values from the input data set row.
Detect deleted row(s) from comparison table
(Optional) Generates DELETEs for all rows that are in the comparison table and not in the input set.
Assumes the input set represents the complete data set. By default this option is turned off.
Assumes the input set represents the complete data set. By default this option is turned off.
So let me explain you this table comparison in an example where I will be demonstrating on a
function called “New Function Call”.
function called “New Function Call”.
New_Function_Call function is used to call a new value as an out put column in the schema out of
a normal query transform.
a normal query transform.
Pre-Requisite :-
Source table / Spreadsheet (Input Data)Permanent table (should have the same structure as the
source table and the spread sheet data to be loaded in to this table) The scenario is that we will be
loading the data from the source table/ Flat file to a permanent table which will be used as a lookup
table later in the job. Note that the source table and the permanent table,both should have the same
structure including the field names and the data types and lengths.
source table and the spread sheet data to be loaded in to this table) The scenario is that we will be
loading the data from the source table/ Flat file to a permanent table which will be used as a lookup
table later in the job. Note that the source table and the permanent table,both should have the same
structure including the field names and the data types and lengths.
Demo:-
Drag the source Flat File/ Table in to the designer window from your “data store”.
Drag a simple query to do a simple map.
(Do one to one mapping & this query is used to change the name,data type &length of fields if they
do not match with permanent table)Drag one more query to validate and name it as query_validate.
Drag a simple query to do a simple map.
(Do one to one mapping & this query is used to change the name,data type &length of fields if they
do not match with permanent table)Drag one more query to validate and name it as query_validate.
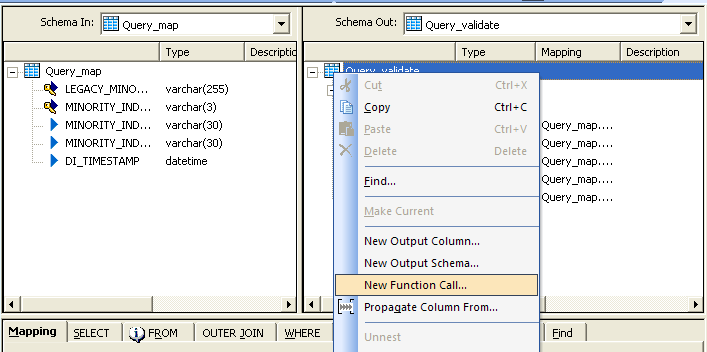
Query_Validation
Here double click on the query validate and open the query.In schema in you will have the fields and
select the schema out and right click. Select new function call as shown below
select the schema out and right click. Select new function call as shown below
And the below Screen will open
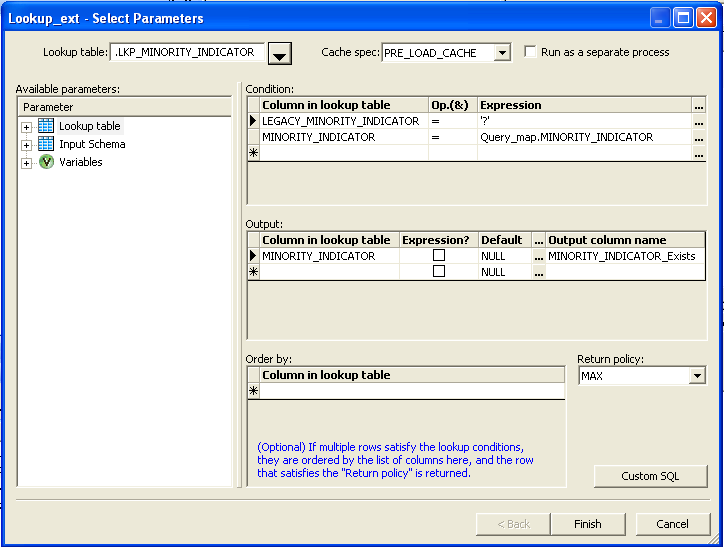
Click on  next to the lookup table and select the data store which have your permanent table
next to the lookup table and select the data store which have your permanent table
and open that and select the actual lookup table and click on ok.
and open that and select the actual lookup table and click on ok.
Now click in the first row under the “Column in lookup table”, under conditions and select the
drop down and select the primary key. Next, select “=” under the operation and now drag the
same primary key from the input schema under the expression.
drop down and select the primary key. Next, select “=” under the operation and now drag the
same primary key from the input schema under the expression.
Now click on the “Column in lookup table” under the Output and select the primary key field and
change the name of the field under the Output column name to field name_exists.Now click on finish
change the name of the field under the Output column name to field name_exists.Now click on finish
This function will help us to cross check the primary key field from input table,with the permanent
table’s primary key and check if the data is same or not(picks the common data from both tables).
If it exists, it will pass the existing value, else it will be passed as null.
table’s primary key and check if the data is same or not(picks the common data from both tables).
If it exists, it will pass the existing value, else it will be passed as null.
Validation
Next we do a validation to the field “Primary key_Exists”check if this is not null.The pass records will
go to the “Table comparison” & the failed will go to the query which will update the failed records to
the valid failure table.
go to the “Table comparison” & the failed will go to the query which will update the failed records to
the valid failure table.
Table comparison
Drag the table comparison transform from the query transform under the local object library ,
to the designer screen and now connect the valid pass to the Table comparison.
Click on the table comparison transform to open that and you will find the below screen.
to the designer screen and now connect the valid pass to the Table comparison.
Click on the table comparison transform to open that and you will find the below screen.
As per the previous intro about the table comparison at the beginning of the document,
we will get some imp points like
we will get some imp points like
Note: If you choose the Detect Deleted row(s) from comparison table option, then the performance
of the data flow will be slower. The comparison method most affected is the Row-by-row select,
followed by Cached compare table, then Sorted input option. For Row-by-row select and Cached
compare table, Data Services processes the deleted rows at the end of the data flow.
For Sorted input,Data Services processes deleted rows as they are encountered in the data flow.
of the data flow will be slower. The comparison method most affected is the Row-by-row select,
followed by Cached compare table, then Sorted input option. For Row-by-row select and Cached
compare table, Data Services processes the deleted rows at the end of the data flow.
For Sorted input,Data Services processes deleted rows as they are encountered in the data flow.
Click on  next to Table name under the table comparison tab and first select the Data store and
next to Table name under the table comparison tab and first select the Data store and
then open the data store to select the appropriate lookup table (permanent).
then open the data store to select the appropriate lookup table (permanent).
Note: - Only the permanent tables will be available under the Data stores here.
You can use the Generate Key column if you want to generate the key values on
any fields other than the date fields.
any fields other than the date fields.
Next select row_by_row check box and if you want your data to contain the duplicate keys you can
check on the check box for input contains duplicate keys.
check on the check box for input contains duplicate keys.
Drag the remaining fields to the compare columns if you want transform to compare more effectively
You can select the check box run as a separate process to improve the performance if you are doing
a comparison on many fields.
a comparison on many fields.
Go back by clicking on  and join the table comparison transform to the map_operation transforms
and join the table comparison transform to the map_operation transforms
to avail the Insert, Update and Delete operands on the compared set of data.
to avail the Insert, Update and Delete operands on the compared set of data.
Merge
Drag merge transform to combine the map_operations and now link the merge to the output table.
Note: -
this output table will be the same table that you choose under the data store in the table comparison
transform. So we need to drag the permanent table from the Data store under the local object library
and connect / link that to merge operation.
this output table will be the same table that you choose under the data store in the table comparison
transform. So we need to drag the permanent table from the Data store under the local object library
and connect / link that to merge operation.
This concludes the process of extracting the data from the flat file and doing
- Query_map (to do one to one mapping )
- Query_Validate (to validate if the common data exists using the new function call)
- Validate (to pass the valid records to the table comparison and invalid to fail table)
- Table comparison (to do a comparison on the data sets)
- Map_operation (to facilitate the operands insert, update , delete and discard on the data
- Merge (to combine the map operations and connect that to the permanent table)
Now you can run the job to populate the data and you can also run the job in de-bug mode to check
the actual flow and changes in the data.
the actual flow and changes in the data.