
 Map_CDC_Operation
Map_CDC_Operation
Using its input requirements (values for the Sequencing column and a Row operation column),
performs three functions:
performs three functions:
- Sorts input data based on values in Sequencing column box and (optional) the Additional Grouping Columns box.
- Maps output data based on values in Row Operation Column box. Source table rows are mapped to INSERT, UPDATE, or DELETE operations before passing them on to the target.
- Resolves missing, separated, or multiple before- and after-images for UPDATE rows.
This Transformation is used to perform the CDC comparing the Image of the source table with the
Image of the target table.
Image of the target table.
While commonly used to support relational or mainframe changed-data capture (CDC),this transform
supports any data stream as long as its input requirements are met. Relational CDC sources include
Oracle and SQL Server. This transform is typically the last object before the target in a data flow
because it produces INPUT, UPDATE and DELETE operation codes. Data Services produces a warning
if other objects are used.
Options
Sequencing column
(Required) Specifies an integer used to order table rows.
If you are using a relational or mainframe CDC source table, the DI_SEQUENCE_NUMBER column is
automatically selected as the Sequencing column.
automatically selected as the Sequencing column.
Input already sorted by sequencing column
This transform by default assumes that the input data is already sorted based on the value selected
in the Sequencing column box. If you deselect this check box, Data Services will re-sort the input
data using the value in the Sequencing column box.Use the re-sort capability of this transform only
when necessary as it impacts job performance.
in the Sequencing column box. If you deselect this check box, Data Services will re-sort the input
data using the value in the Sequencing column box.Use the re-sort capability of this transform only
when necessary as it impacts job performance.
Additional grouping columns
In addition to the Sequencing column, you can sort input on additional columns by dragging them
into this box from the input schema. Sorts are prioritized based first on the sequencing column
and then on the order of the columns added to this box.
into this box from the input schema. Sorts are prioritized based first on the sequencing column
and then on the order of the columns added to this box.
Row operation column
(Required) Specifies a column with one of the following output operation codes for each row:
- I for INSERT
- B for before-image of an UPDATE
- U for after-image of an UPDATE
- D for DELETE
If you are using a relational or mainframe CDC source table, the DI_OPERATION_TYPE column is
automatically selected as the Row operation column.
automatically selected as the Row operation column.
Demonstration:- (Job)
Create a job as below
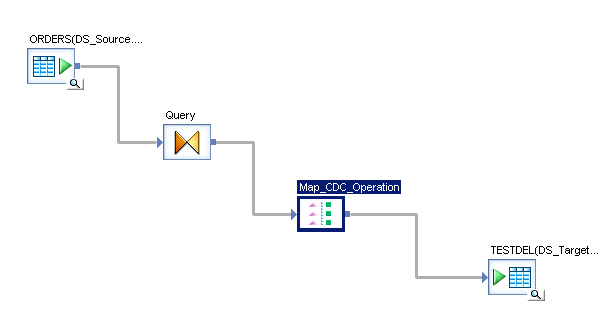
In the Query Transformation add 2 fields (new output columns) and map them as below
- DI_SEQUENCE_NUMBER :- Map this with the function “ Gen_row_number ( )
- DI_OPERATION_TYPE :-
Map this with any one of the operation codes ( ‘I’,’U’,’D’,’B’)
- I for INSERT
- B for before-image of an UPDATE
- U for after-image of an UPDATE
- D for DELETE
Please find the screenshot below

In the Transformation “ Map_CDC_Operation” do the following mapping.
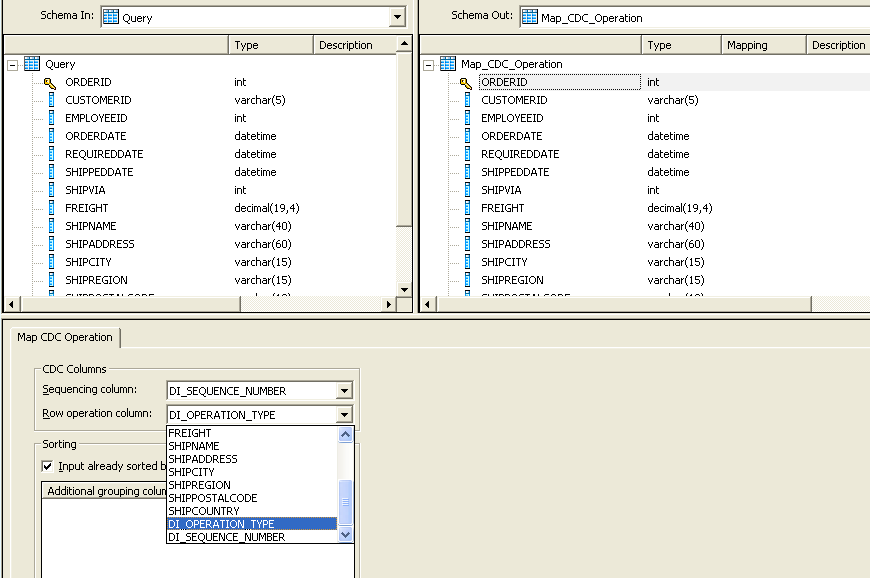
Select the respective fields for Sequence and the Row Operation columns
Sequencing Column → DI_Sequence_Number
Row Operation Column → DI_Operation_Type
Save and execute the job and check the values in the target table.
The records will be inserted in to the target table.
Now go to Query Transformation and change the value of DI_Operation_Type to ‘D’ and once again
execute the job.
Check the target tables values and you will notice the data is deleted from the target table because
of the operation code that you used in the query transformation.
Note:- Please note that target table is a permanent table