
Data Quality
 Match Transformation
Match Transformation
Match transformation is used to identify the Duplicates in the data based on the match criteria and
the weighted score.
the weighted score.
This transformation is used to determine the duplicates and consolidate the duplicates in them.
Using this transform we can,
Correct and standardize the data
Employ the match standards
Fill Empty / Null records
Define a match strategy
Break Group: - Using the break group, we can break the data in to groups or buckets so that later
when we want to do a comparison, the comparison happens with in that group or bucket.
when we want to do a comparison, the comparison happens with in that group or bucket.
First record among the duplicates will become the master and the remaining records will become the
subordinate records.
subordinate records.
We will see the Match Wizard for using the match transformation.
Create a batch job (Job_demo_match_Bstrec), Data flow (DF_match_br)
Here in this example we are using the excel spread sheet as source, so import that spread sheet to
data services through file format and use it as source in the dataflow.
data services through file format and use it as source in the dataflow.
Sample source data:-

These types of records are potential duplicates as the system cannot identify them as Duplicatedata.
Using the BODS Match Transform we can identify such records based on the match strategy, match
scores and match ranks. It also picks the first record as the master record and the remaining
duplicates as the subordinate records. (Address and the phone columns)
Now select the source and right click and choose Run match wizard.
This will start the Match wizard.
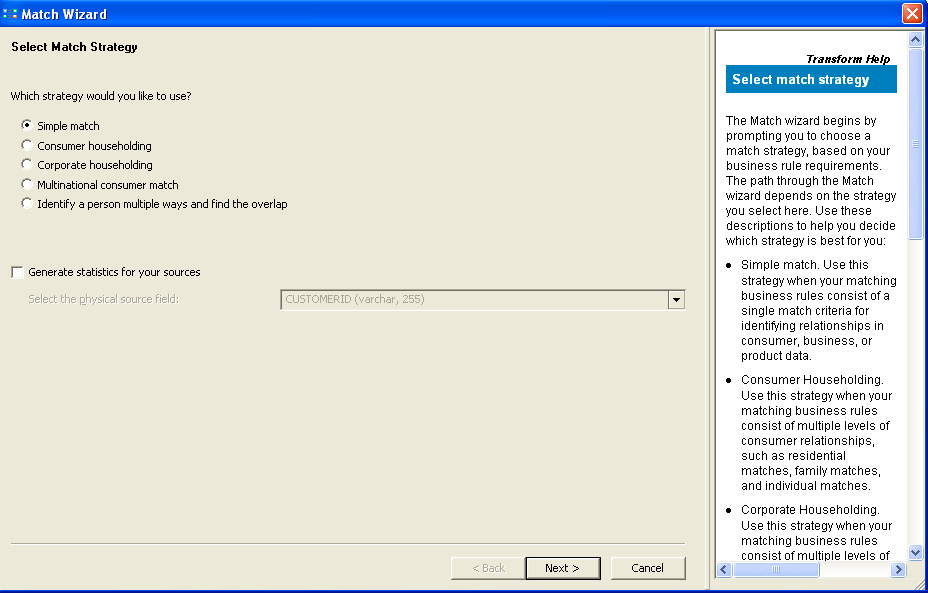
Select the simple match and click on next.
Now we have to identify the match criteria, you can define more than one criteria at this stage on
which you have to define the match.
which you have to define the match.
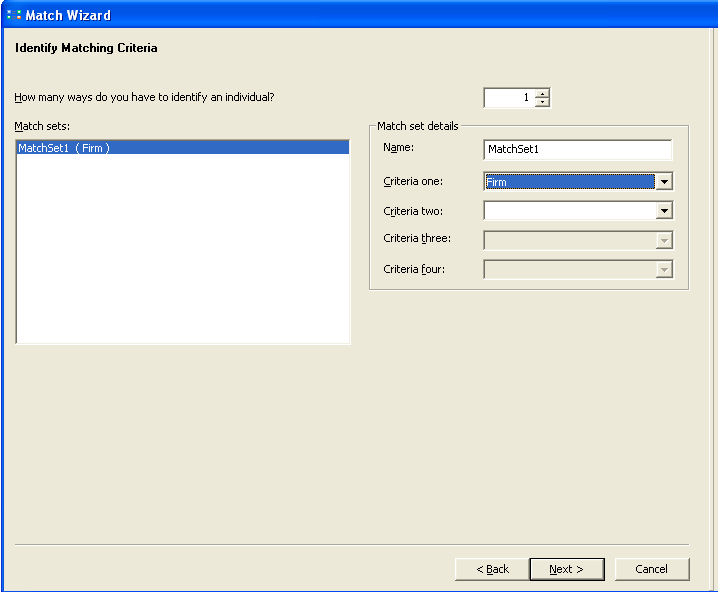
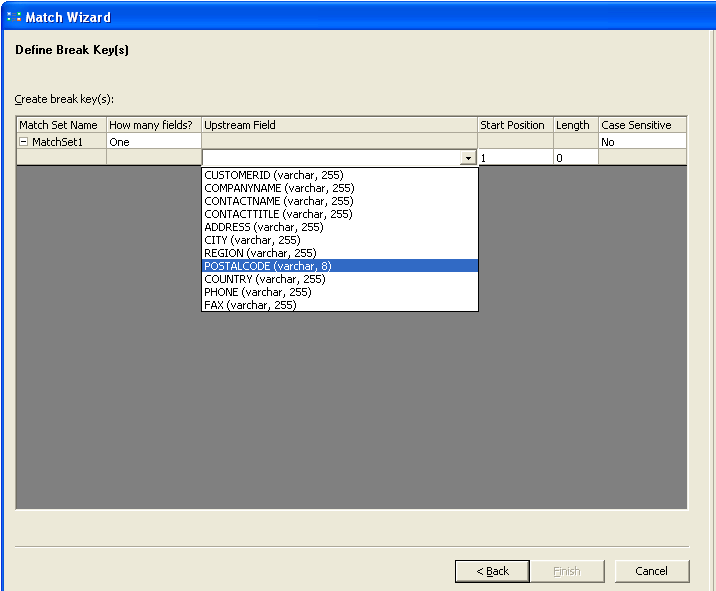
Give the match set name and select the criteria from the drop down. Click on next.
Here we are trying to a match on the data to identify the duplicates bydefining match criteria asFIRM

Select the drop down next to firm and choose the field company name from the source and
click on next.Now we need to define the break key.
As per the earlier def, the break key creates breaks the data in to different buckets,
so that when we can quickly perform the duplicate check, if searched with in the bucket.
This reduces the comparison and improves the performance. Here we are creating a break key on
postal code. Give length to 5 and click Finish.
This completes the creation of match transformation. Drag a temp table from the right side pane and
link the match transformation to the temp table and execute the job to see the result.
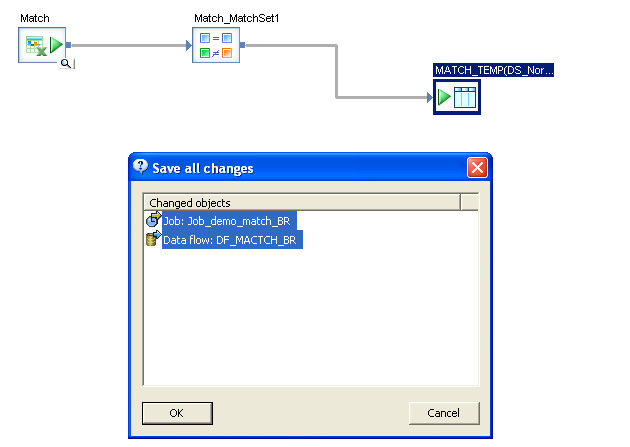
Save and execute the job to see the results of the match transformation.

The group number defines the number of groups of potential duplicates
Group number, score, count, and rank are the extra fields that are added and based on them
you can identify the duplicates.
you can identify the duplicates.
Group number give break group number (here it is based on the postal c0de)
Match score gives the percentage of match (here its 100% match)
The last one rank identifies the master and the subordinate records.
Best Record:-
This is the process by which you identify the partially filled records from a bucket or a group
and try to create a complete record (master) by filling those values form the subordinates’ records.
and try to create a complete record (master) by filling those values form the subordinates’ records.
For example.
Click on the match transformation and go to options tab and click edit options button or
right click on the transformation and click on “match editor” to create the best record strategy.
right click on the transformation and click on “match editor” to create the best record strategy.
Best record is a post match processing.
So we need to add fields Address and phone number to the input tab of the match transformation.
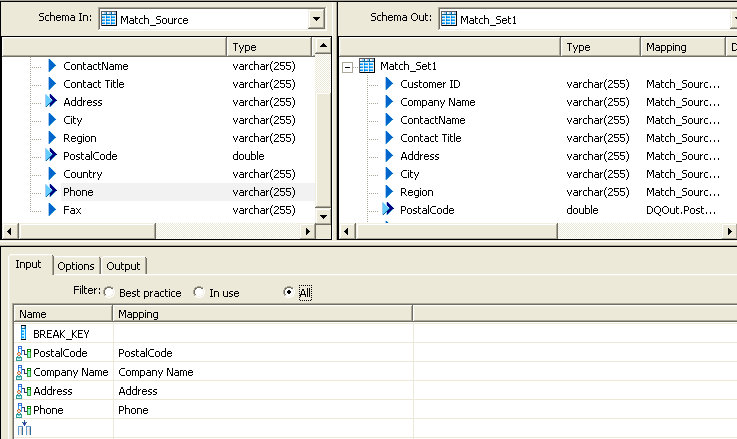
Drag and drop the fields Address and phone number to the Input tab as above.
Go to options tab and click on edit options button.
Go to options tab and click on edit options button.
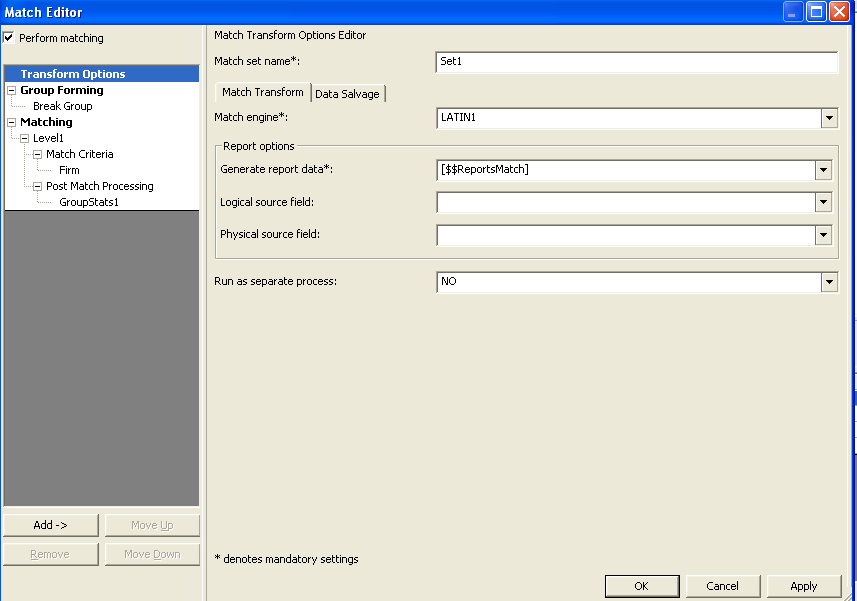
Right click on the Post match processing → add → Best Record

Now you will see the bellow screen.
Change the best record name as Addr_Best_Record as we are doing this for the Address Column
and choose the values as bellow from the drop down.
and choose the values as bellow from the drop down.
Best record strategy: - Non-Blanks (a row with no blanks is a best record)
Strategy field:- Address ( as we are doing the best record for the address)
Posting per Destination: - Master (because we want to create the master record as the best record)
Post only once per Destination: - Yes
Best record action fields
Choose Address from the drop down in the source field and automatically the Address
in the Destination Field is selected.
Choose Yes for the custom if you want to wrote any custom python code and No if you don’t wish to.
in the Destination Field is selected.
Choose Yes for the custom if you want to wrote any custom python code and No if you don’t wish to.
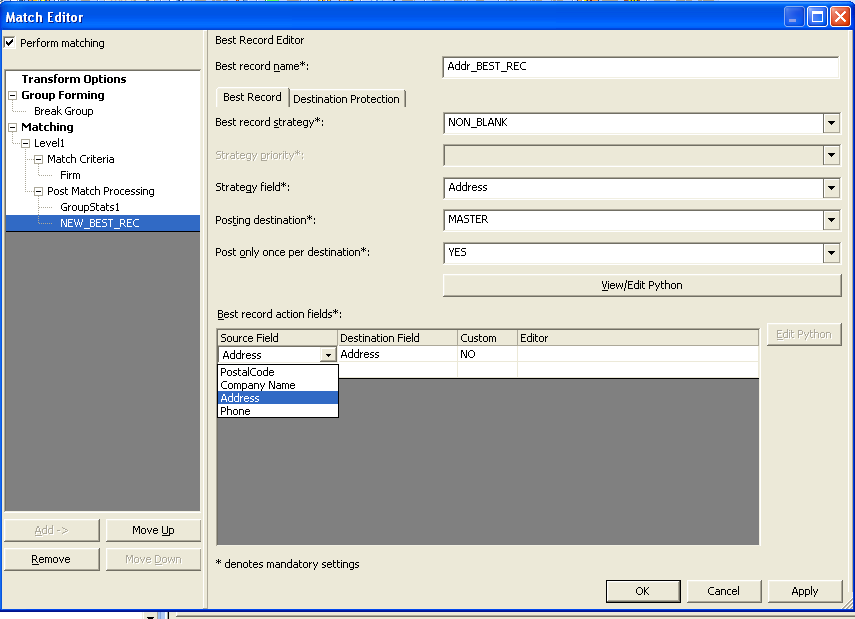
Click on Apply and ok.
Repeat the same process for the field Phone for the best record.
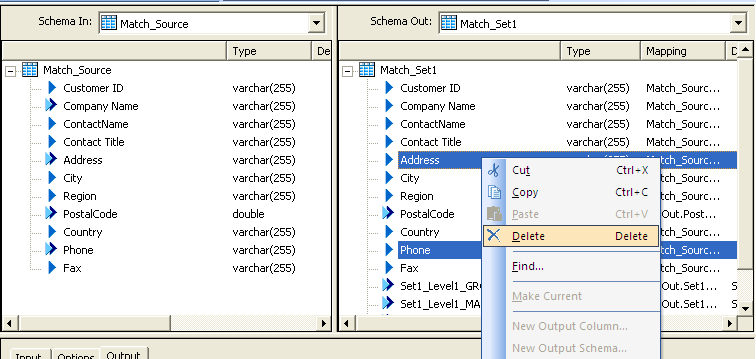
Delete the fields Address and Phone from Schema out
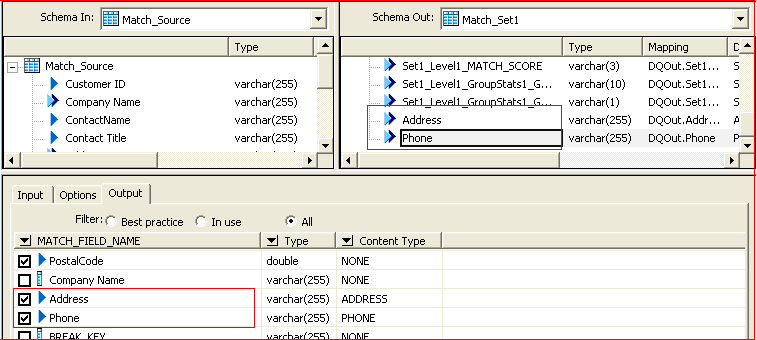
Now go to the Output tab and choose the fields (address and phone) you want to display in the
schema out. These columns will display the new best record values.
Save and execute the job so see the bellow results in the target table.

Now you can notice that the Address and the Phone values are posted in the master record.
You can also uncheck the fields Group number, score, count and rank if you don’t wish them
to be displayed in the target table.
to be displayed in the target table.